

Cybersecurity researchers are warning about the security risks in the machine learning (ML) software supply chain following the discovery of more than 20 vulnerabilities that could be exploited to target MLOps platforms.
These vulnerabilities, which are described as inherent- and implementation-based flaws, could have severe consequences, ranging from arbitrary code execution to loading malicious datasets.
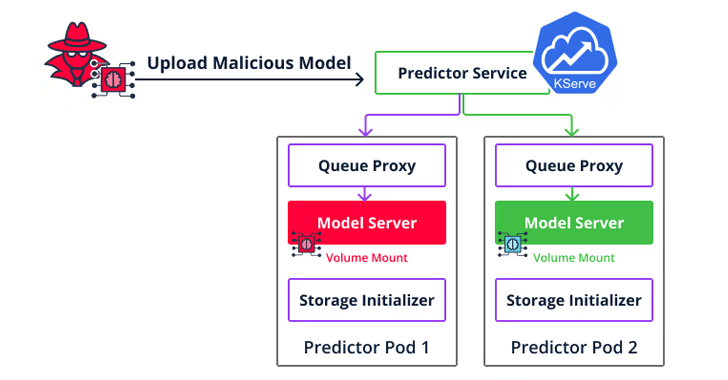
MLOps platforms offer the ability to design and execute an ML model pipeline, with a model registry acting as a repository used to store and version-trained ML models. These models can then be embedded within an application or allow other clients to query them using an API (aka model-as-a-service).
“Inherent vulnerabilities are vulnerabilities that are caused by the underlying formats and processes used in the target technology,” JFrog researchers said in a detailed report.
Some examples of inherent vulnerabilities include abusing ML models to run code of the attacker’s choice by taking advantage of the fact that models support automatic code execution upon loading (e.g., Pickle model files).
This behavior also extends to certain dataset formats and libraries, which allow for automatic code execution, thereby potentially opening the door to malware attacks when simply loading a publicly-available dataset.
Another instance of inherent vulnerability concerns JupyterLab (formerly Jupyter Notebook), a web-based interactive computational environment that enables users to execute blocks (or cells) of code and view the corresponding results.
“An inherent issue that many do not know about, is the handling of HTML output when running code blocks in Jupyter,” the researchers pointed out. “The output of your Python code may emit HTML and [JavaScript] which will be happily rendered by your browser.”
The problem here is that the JavaScript result, when run, is not sandboxed from the parent web application and that the parent web application can automatically run arbitrary Python code.
In other words, an attacker could output a malicious JavaScript code such that it adds a new cell in the current JupyterLab notebook, injects Python code into it, and then executes it. This is particularly true in cases when exploiting a cross-site scripting (XSS) vulnerability.
To that end, JFrog said it identified an XSS flaw in MLFlow (CVE-2024-27132, CVSS score: 7.5) that stems from a lack of sufficient sanitization when running an untrusted recipe, resulting in client-side code execution in JupyterLab.
“One of our main takeaways from this research is that we need to treat all XSS vulnerabilities in ML libraries as potential arbitrary code execution, since data scientists may use these ML libraries with Jupyter Notebook,” the researchers said.
The second set of flaws relate to implementation weaknesses, such as lack of authentication in MLOps platforms, potentially permitting a threat actor with network access to obtain code execution capabilities by abusing the ML Pipeline feature.
These threats aren’t theoretical, with financially motivated adversaries abusing such loopholes, as observed in the case of unpatched Anyscale Ray (CVE-2023-48022, CVSS score: 9.8), to deploy cryptocurrency miners.
A second type of implementation vulnerability is a container escape targeting Seldon Core that enables attackers to go beyond code execution to move laterally across the cloud environment and access other users’ models and datasets by uploading a malicious model to the inference server.
The net outcome of chaining these vulnerabilities is that they could not only be weaponized to infiltrate and spread inside an organization, but also compromise servers.
“If you’re deploying a platform that allows for model serving, you should now know that anybody that can serve a new model can also actually run arbitrary code on that server,” the researchers said. “Make sure that the environment that runs the model is completely isolated and hardened against a container escape.”
The disclosure comes as Palo Alto Networks Unit 42 detailed two now-patched vulnerabilities in the open-source LangChain generative AI framework (CVE-2023-46229 and CVE-2023-44467) that could have allowed attackers to execute arbitrary code and access sensitive data, respectively.
Last month, Trail of Bits also revealed four issues in Ask Astro, a retrieval augmented generation (RAG) open-source chatbot application, that could lead to chatbot output poisoning, inaccurate document ingestion, and potential denial-of-service (DoS).
Just as security issues are being exposed in artificial intelligence-powered applications, techniques are also being devised to poison training datasets with the ultimate goal of tricking large language models (LLMs) into producing vulnerable code.
“Unlike recent attacks that embed malicious payloads in detectable or irrelevant sections of the code (e.g., comments), CodeBreaker leverages LLMs (e.g., GPT-4) for sophisticated payload transformation (without affecting functionalities), ensuring that both the poisoned data for fine-tuning and generated code can evade strong vulnerability detection,” a group of academics from the University of Connecticut said.
Found this article interesting? Follow us on Twitter and LinkedIn to read more exclusive content we post.



{kind=link}
{kind=link}